Probability and Bayesian Networks
Uncertainty
Why is uncertainty important?
- Agents and humans don’t know everything
- but need to make decisions anyways!
- Decisions are made in the absence of information
The best an agent can do: - Know how uncertain it is, and act accordingly
Probability
Frequentist vs. Bayesian
Frequentist view:
- Probability of heads = # of heads / # of flips
- probability of heads this time = probability of heads (history)
- Uncertainty is ontological:
- pertaining to the world
Bayesian view:
- Probability of heads this time = agent’s belief about flip
- Belief of agent A:
- based on previous experience of agent A
- Uncertainty is epistemological:
- pertaining to knowledge
Probability Measure
If
- it can take on values
, where - assume
is discrete
is the probability that
Joint probabilityis the probability that and at the same time
Axioms of Probability
Axioms are things we have to assume about probability
if and are contradictory - can’t both be true at the same time
Some notes:
- probability between 0-1 is purely convention
means you think a is definitely false means you think a is definitely true means you have belief about the truth of - It does not mean that
is true to some degree, just that you are ignorant of its truth value
- It does not mean that
- Probability = measure of ignorance
Independence
Describe a system with
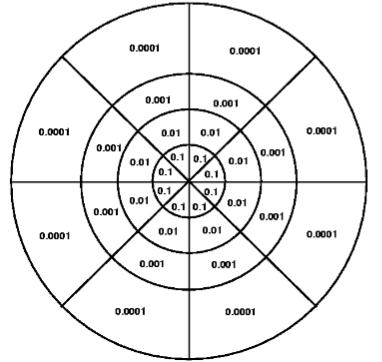
- Use independence to reduce number of probabilities
- e.g. radially symmetric dartboard, P(hit a sector)
where and - 32 sectors in total - need to give 31 numbers
- Assume radial independence:
- only need 7 + 3 = 10 numbers


- only need 7 + 3 = 10 numbers
- e.g. radially symmetric dartboard, P(hit a sector)
Conditional Probability
If
is the probability that given that
Incorporate Independence:- assuming all birds have feathers
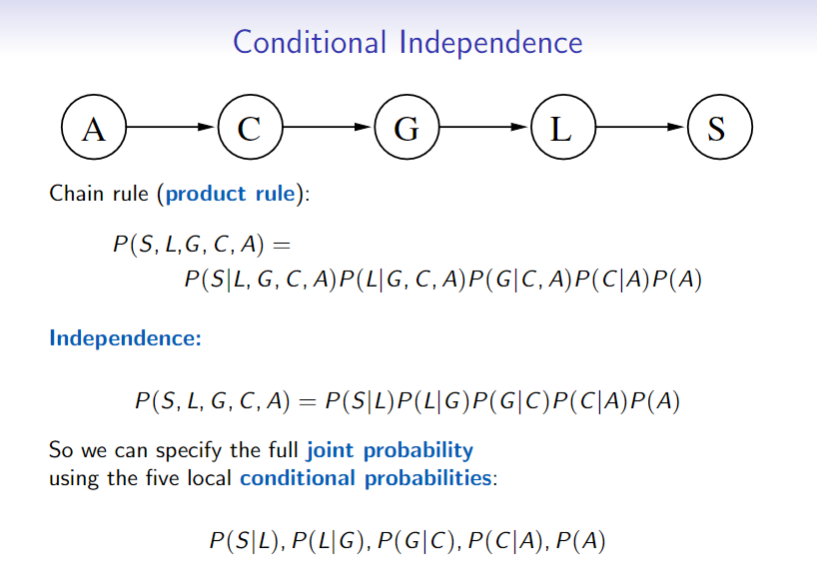
Product Rule (Chain Rule):
- assuming all birds have feathers
Leads to: Bayes’ Rule
Sum Rule
We know
and therefore that
This means that (Sum Rule)
We call
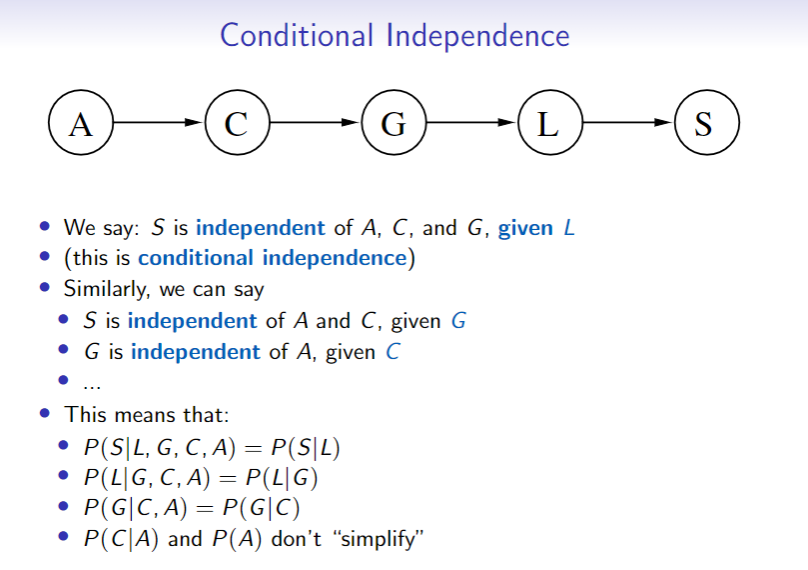
Conditional Independence
- So learning
doesn’t influence beliefs about
and are conditionally independent give iff - So learning
doesn’t influence beliefs about if you already know - does not mean
and are independent
- does not mean
Expected Values
Expected value of a function on
where
This is useful in decision making
- where
is the utility of situation
Bayesian decision making is then
Value of Independence
- Complete independence reduces both representation and influence from
to - Unfortunately, complete mutual independence is rare
- Fortunately, most domains do exhibit a fair amount of conditional independence
- Bayesian Networks or Belief Networks encode this information
Bayesian Networks
Bayesian Networks or Belief Networks
- Directed Acyclic Graph
- Encodes independencies in a graphical format
- Edges give
Example

Correlation and Causality
Directed links in Bayes’ net
- However, not always the case
In a Bayes net, it doesn’t matter - But, some structures will be easier to specify
Example


A Bayesian Network or BN over variables
- a DAG whose nodes are the variables
- a set of Conditional Probability Tables (CPTs) giving
for each
Example probability tables for the Coffee Bayes Net:
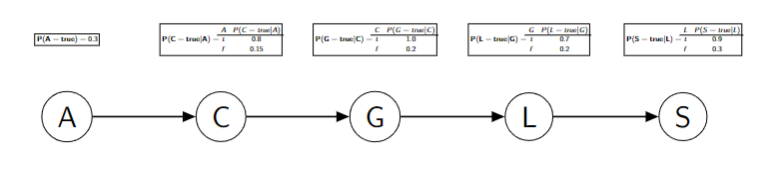
Semantics of a Bayes’ Net
every
for any subset
The BN defines a factorization of the joint probability distribution
- The joint distribution is formed by multiplying the conditional probability tables together
Constructing Belief Networks
To represent a domain in a belief network, you need to consider:
- What are the relevant variables?
- What will you observe?
- this is the evidence
- What would you like to find out?
- this is the query
- What other features make the model simpler?
- these are the other variables
- What will you observe?
- What values should these variables take?
- What is the relationship between them?
- this should be expressed in terms of local influence
- How does the value of each variable depend on its parents?
- this is expressed in terms of the conditional probabilities
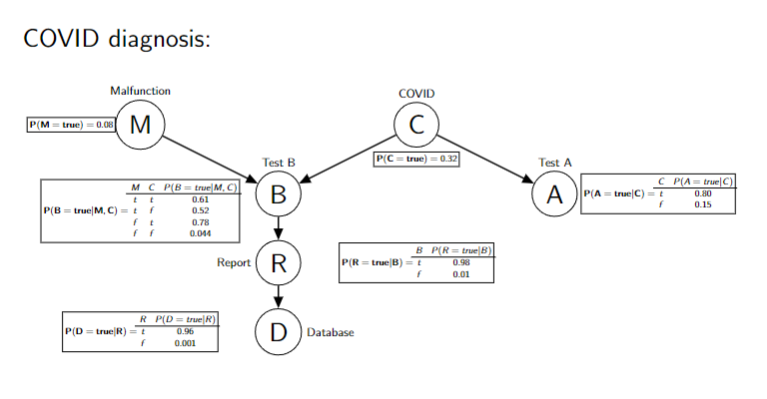
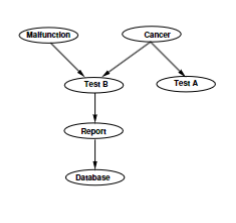
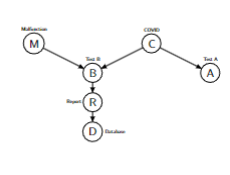
Three Basic Bayesian Networks
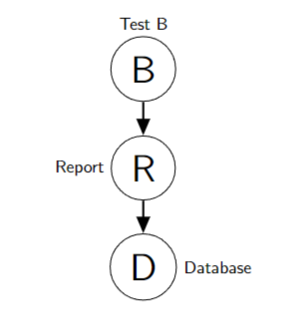
- Database and Test B independent if Report is observed
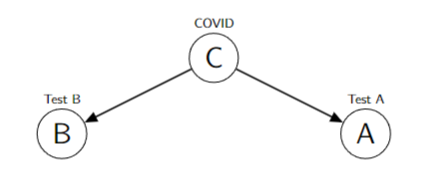
- Test B and Test A independent if COVID is observed
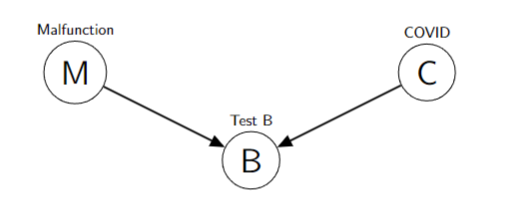
- Malfunction and COVID are independent if Test B is not observed
Updating Belief: Bayes’ Rule
Agent has a prior belief in a hypothesis,
- Agent observes some evidence
that has a likelihood given the hypothesis:
The agent’s posterior belief aboutafter observing $e, is given by Bayes’ Rule:
- Useful when we have causal knowledge and want to do evidential reasoning
Probabilistic Inference
Simple Forward Inference (Chain)
Computing marginal requires simple forward propagation of probabilities
- marginalization - sum rule
- chain rule
- independence
- distribution of product over sum
Same idea when evidence
- marginalization
- chain rule
- independence and conditional independence
With multiple parents the evidence is “pooled”
Also works with “upstream” evidence
Simple Backward Inference
When evidence is downstream of query, then we must reason “backwards”.
- This requires Bayes’ rule
Normalizing constant is
Variable Elimination
More general algorithm:
- applies sum-out rule repeatedly
- distributes sums
Factors
a factor is a representation of a function from a tuple of random variables into a number
- We will write factor
on variables as - We can assign some or all of the variables of a factor
- this is restricting a factor:
, where , is a factor on is a number that is the value of when each has value
The former is also written as, etc.
- this is restricting a factor:
Multiplying Factors
The product of factor
Summing out variables
We can sum out a variable, say
Evidence
If we want to compute the posterior probability of
The computation reduces to the joint probability of
- can also restrict the query variable
- e.g. compute:
- e.g. compute:
Probability of a conjunction
Suppose the variables of the belief network are
- To compute
, we sum out the variables other than query and evidence - We order the
into an elimination ordering
Computing sums of products
Computation in belief networks reduces to computing the sums of products
- How can we compute
efficiently? - Distribute out the
giving
- Distribute out the
- How can we compute
efficiently? - Distribute out those factors that don’t involve
- Distribute out those factors that don’t involve
Variable Elimination Algorithm
To compute
- Construct a factor for each conditional probability
- Restrict the observed variables to their observed values
- Sum out each of the other variables according to some elimination ordering:
- for each
in order starting from : - collect all factors that contain
- multiply together and sum out
- add resulting new factor back to the pool
- collect all factors that contain
- for each
- Multiply the remaining factors
- Normalize by dividing the resulting factor
by
Summing our a Variable
To sum out a variable
- Partition the factors into
- those that don’t contain
, say , - those that contain
, say
We know:
- those that don’t contain
- Explicitly construct a representation of the rightmost factor
- Replace the factors of
by the new factor
Notes on Variable Elimination
- Complexity is linear in number of variables, and exponential in the size of the largest factor
- When we create new factors: sometimes this blows up
- Depends on the elimination ordering
- For polytrees:
- work outside in
- For general BNs this can be hard
- simply finding the optimal elimination ordering is NP-hard for general BNs
- inference in general is NP-hard
Variable Ordering
Polytrees
- eliminate singly-connected nodes
first - Then no factor is ever larger than original CPTs
- if you eliminate
first, a large factor is created that includes
- if you eliminate
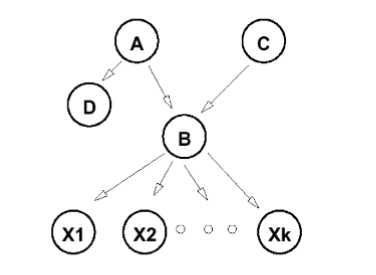
Relevance
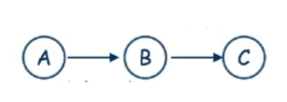
Certain variables have no impact
- In ABC network above, computing
does not require summing over and
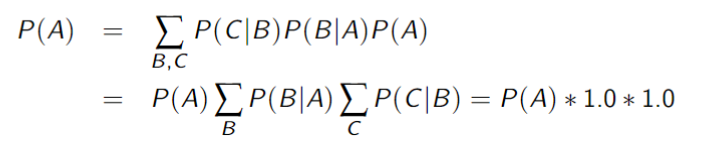
Can restrict attention to relevant variables: - Given query
and evidence , complete approximation is: is relevant - if any node is relevant, its parents are relevant
- if
is a descendent of a relevant variable, then is relevant
Irrelevant variable: a node that is not an ancestor of a query or evidence variable
- This will only remove irrelevant variables, but may not remove them all
Probability and Time
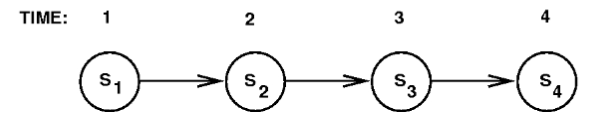
- A node repeats over time
- Explicit encoding of time
- chain has length = amount of time you want to model
- event-driven times or clock-driven times
- e.g. Markov chain
Markov Assumption
This distribution gives the dynamics of the Markov Chain
Hidden Markov Models (HMMs)
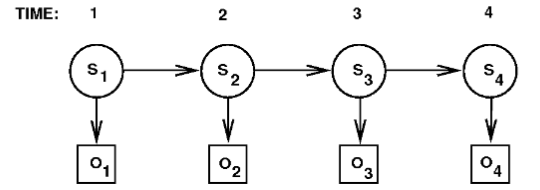
Add: observations
- always observed, so the node is square
Observation function - Given a sequency of observations
, can estimate filtering: - Or smoothing, for
Speech Recognition
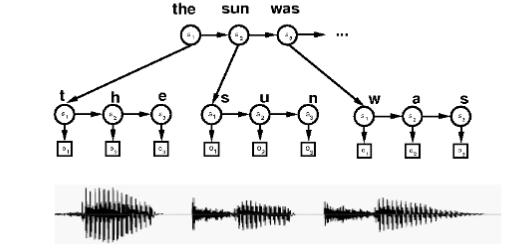
- Observations: audio features
- States: phonemes
- Dynamics: models
- e.g. co-articulation
- HMMs: words
- Can build hierarchical models (e.g. sentences)
Dynamic Bayesian Networks (DBNs)
In general, any Bayesian network can repeat over time: DBN
- Many examples can be solved with variable elimination
- may become too complex with enough variables
- event-drive times or clock-driven times
Stochastic Simulation
Idea: probabilities
- Get probabilities from samples:
- If we could sample from a variable’s (posterior) probability, we could estimate its (posterior) probability
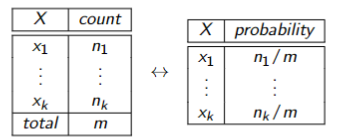
Generating Samples from a distribution
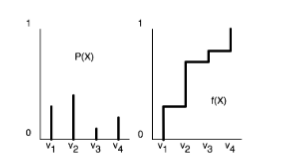
For a variable
- Totally order the values of the domain of
- Generate the cumulative probability distribution:
- Select a value
uniformly in the range - Select
such that
Forward Sampling in a Belief Network
- Sample the variables one at a time;
- Sample parents of
before you sample - Given values for the parents of
, sample from the probability of given its parents
- Given values for the parents of
- for samples
:$$P(X=x_i)\propto \sum_{s_i}\delta(x_i)=N_{X=x_i}$$where if in and 0 otherwise
Example

- A: 2/3 based on first 7 samples