Weight Initialization
What happens if we initialize all W = 0, b = 0?
- Outputs are all going to be 0
- Outputs will not depend on inputs
- Gradients will all be 0
BAD!!!
Initialize with small random numbers
Gaussian with zero mean, std=0.01
W = 0.01 * np.random.randn(Din, Dout)
Works ok for small networks, but problems with deeper networks
- All activations tend to zero for deeper network layers
- Gradients all zero
- No learning

Try larger number (0.01 → 0.05)
W = 0.05 * np.random.randn(Din, Dout)
Too large
- Activations are in saturated regimes
- Local gradients all zero
- No learning

- No learning
Xavier Initialization
W = np.random.randn(Din, Dout) / np.sqrt(Din)
- For conv layers,
Diniskernel_size ** 2 * input_channels
Activations are nicely scaled for all layers!

What about ReLU?
Xavier assumes zero centered activation function
Activations collapse to zero again
- No learning

Kaiming / MSRA Initialization (ReLU)
W = np.random.randn(Din, Dout) / np.sqrt(2 / Din)
ReLU correction: std = sqrt(2 / Din)

Residual Networks
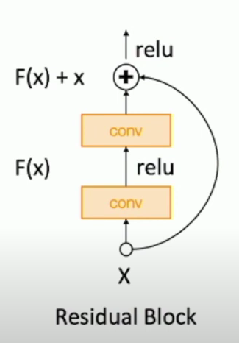
If we initialize with MSRA, then Var(F(x)) = Var(x)
But then Var(F(x) + x) > Var(x)
- Variance grows with each block
Solution
Initialize first conv with MSRA, initialize second conv to zero
Then, Var(x + F(x)) = Var(x)