Videos
A video is a sequence of images
4D tensor: T x 3 x H x W
Video Classification
Fixed size of categories like Image Classification

In video classification, we want to recognize actions
Problem: Videos are big!
Videos are ~30 frames per second
Size of uncompressed video (3 bytes per pixel)":
- SD (640 x 480): ~1.5 GB per minute
- HD (1920 x 1080): ~10 GB per minute
- Low fps
- Low spatial resolution
- e.g. T=16, H=W=112
- 3.2 seconds at 5 fps, 588KB
- e.g. T=16, H=W=112

Testing
Run model on different clips, average predictions

Single-Frame CNN
Idea
Train normal 2D CNN to classify each video frames independently!
- Average predicted probs at test-time
Often a very strong baseline for video classification

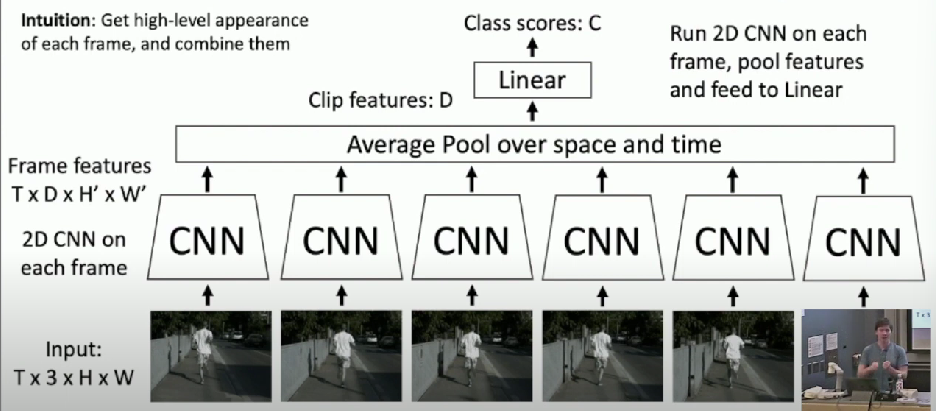
Late Fusion
Intuition
Get high-level appearance of each frame and combine them
With FC Layers
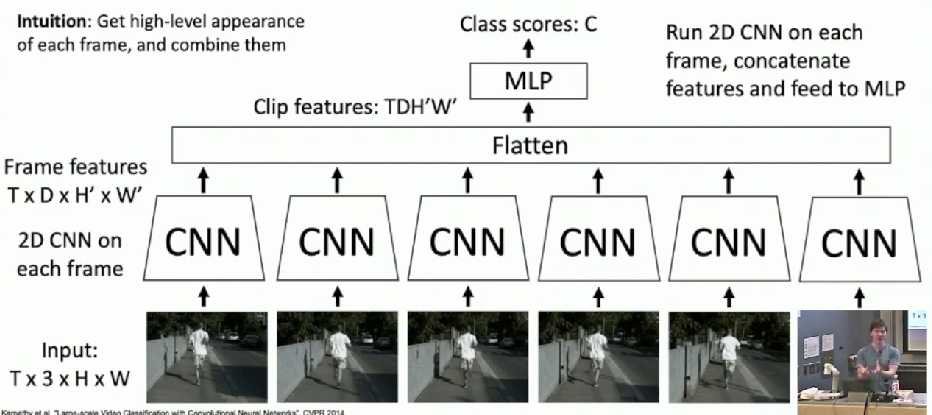
With Pooling
Less learnable parameters compared to FC
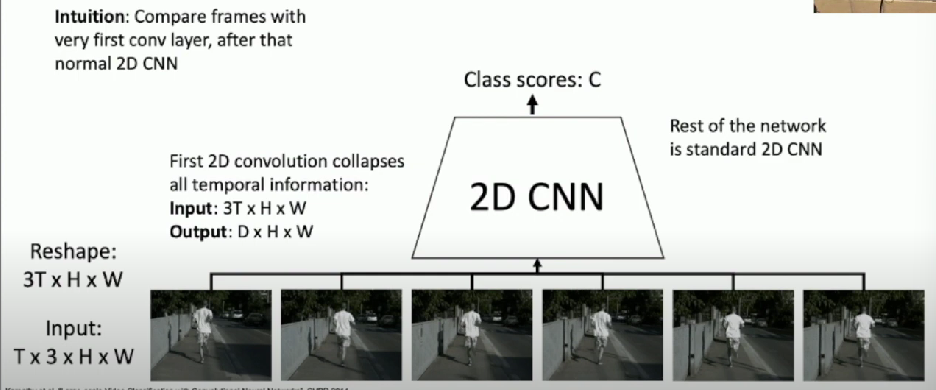
Early Fusion
Intuition
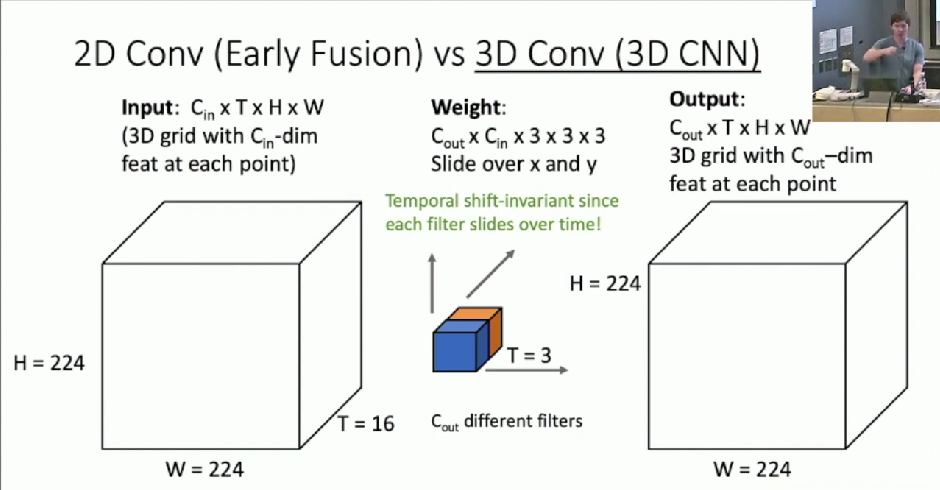
Compare frames with very first conv layer
- after that normal 2D CNN
First 2D convolution collapses all temporal information
3D CNN (Slow Fusion)
Intuition
Use 3D versions of convolution and pooling to slowly fuse temporal information over the course of the network

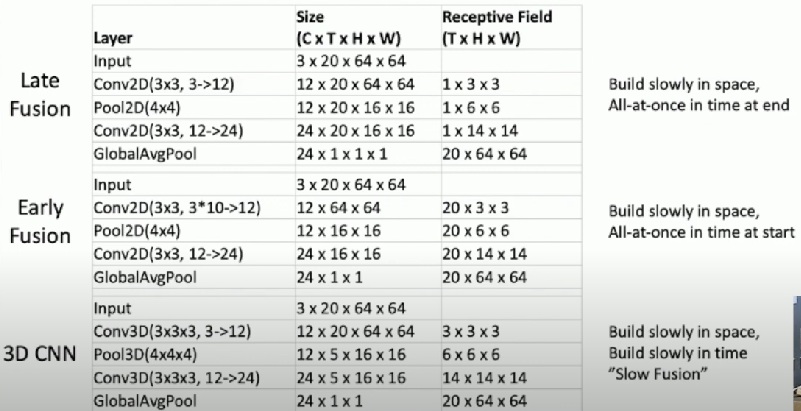
Early Fusion vs Late Fusion vs 3D CNN
Late Fusion
- Build slowly in space
- All-at-once in time at end

Early Fusion
- Build slowly in space
- All-at-once in time at start
3D CNN
- Build slowly in space
- Build slowly in time
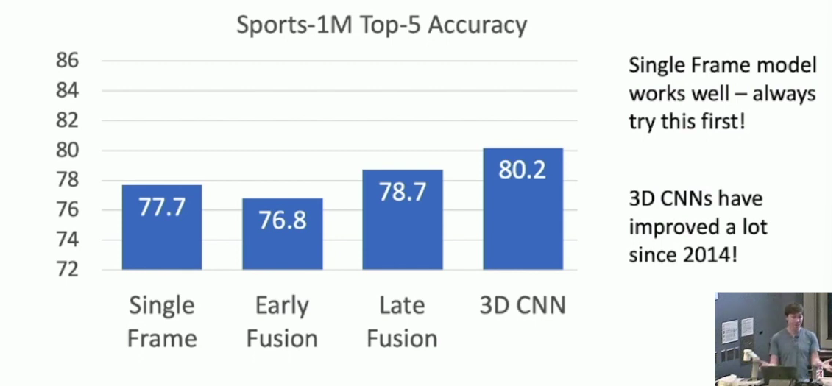
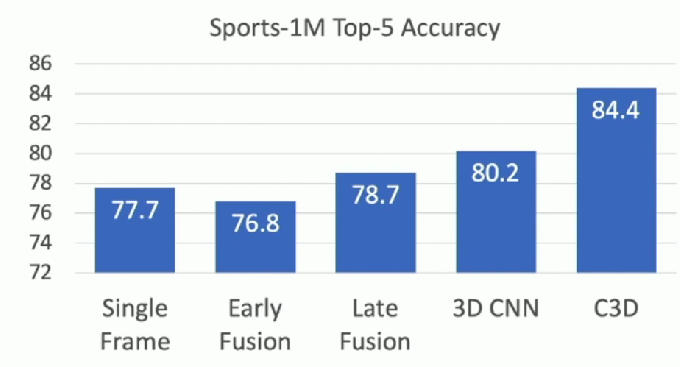
Accuracy
2D Conv vs 3D Conv

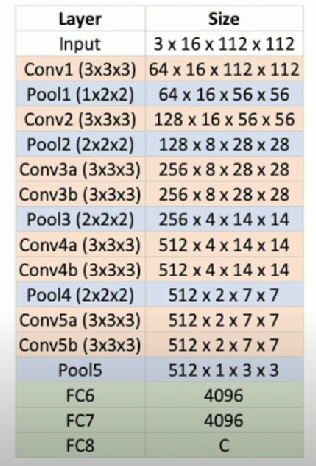
C3D: The VGG of 3D CNNs
3D CNN that uses all 3x3x3 conv and 2x2x2 pooling
- Except Pool1 with 1x2x2
- AlexNet: 0.7GFLOP
- VGG-16: 13.6 GFLOP
- C3D: 39.5 GFLOP
Measuring Motion: Optical Flow
Optical flow gives a displacement field F between images
- Tell where each pixel will move in the next frame
- Vertical and horizontal flow

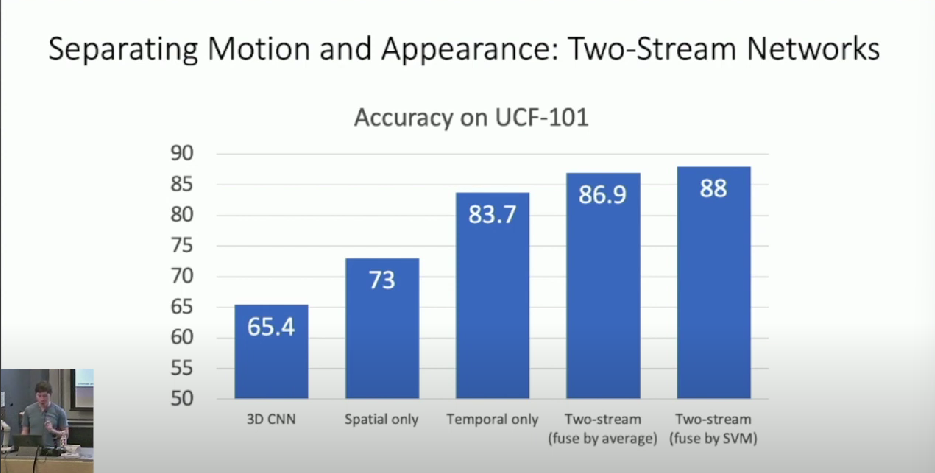
Two-Stream Networks
Separating Motion and Appearance
- Top stream processes appearance of input video
- Lower stream is motion stream
- Processing only motion

- Processing only motion
Performance
Modeling long-term temporal structure
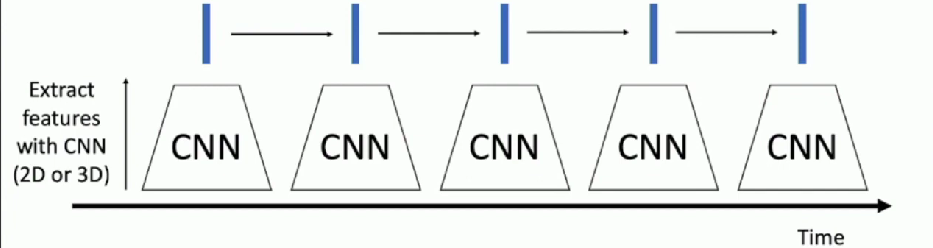
We can handle sequences with Recurrent Neural Networks!
Inside CNN: Each value is a function of a fixed temporal window
Inside RNN: Each vector is a function of all previous vectors
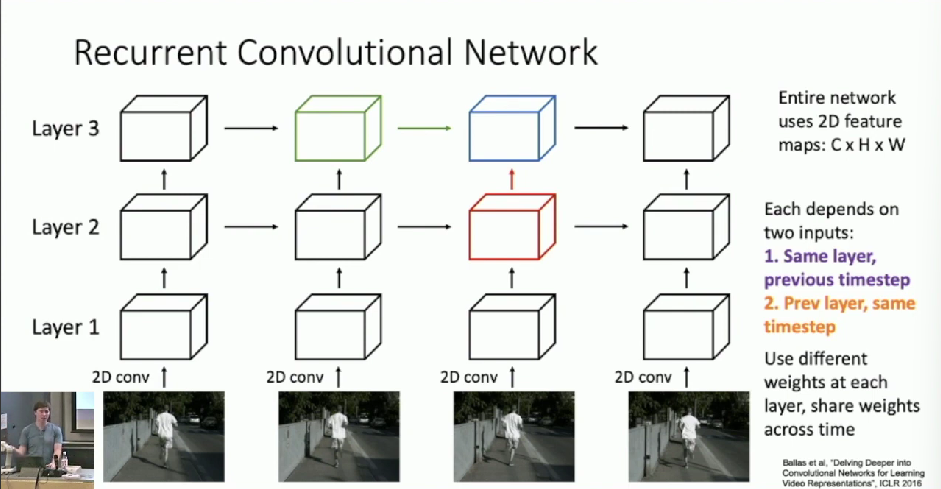
Recurrent Convolutional Network
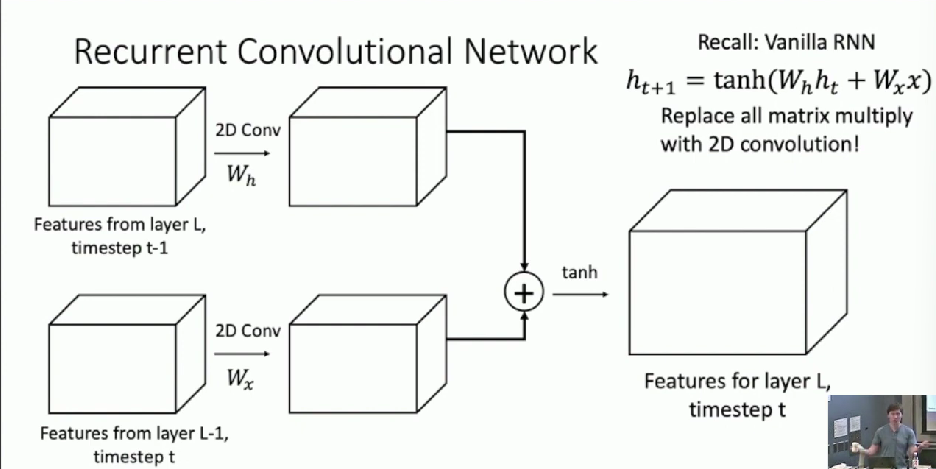
RNNs cannot be parallelized
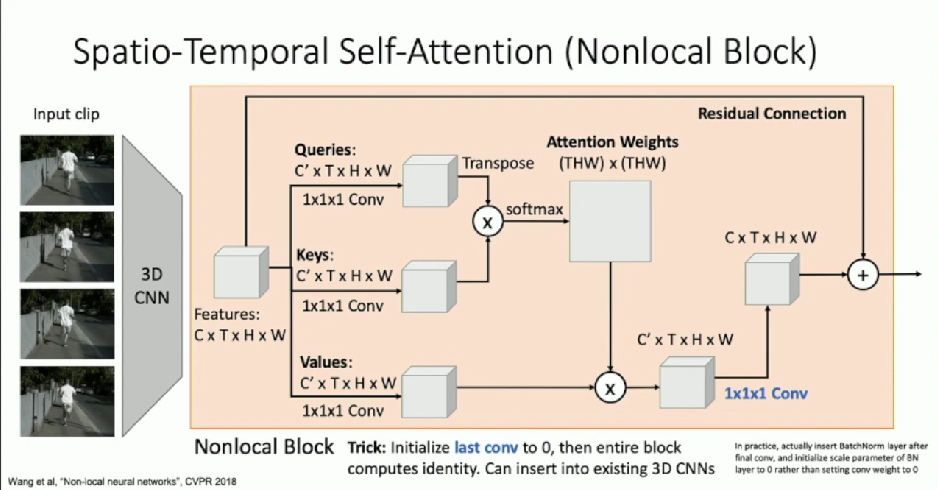
Self-Attention
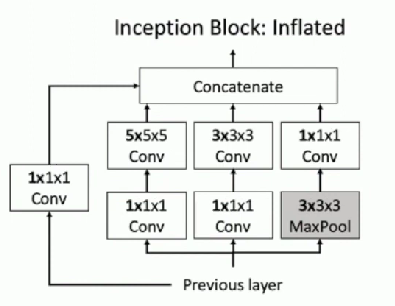
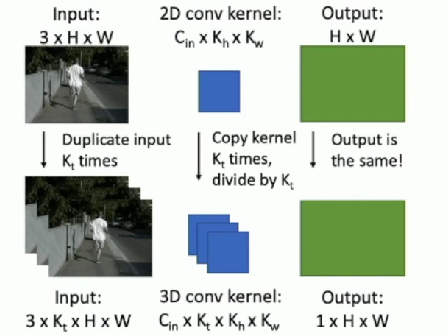
Inflating 2D Networks to 3D (I3D)
Idea
Take a 2D CNN architecture
- Replace each 2D
conv/pool layer with a 3D version
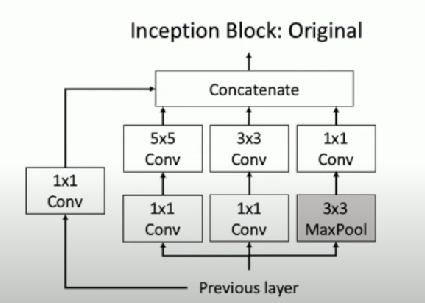
Original
Updated
Transfer Weights
Can use weights to 2D conv to initialize 3D conv
- Copy
times in space and divide by - This gives the same result as 2D conv given “constant” video input
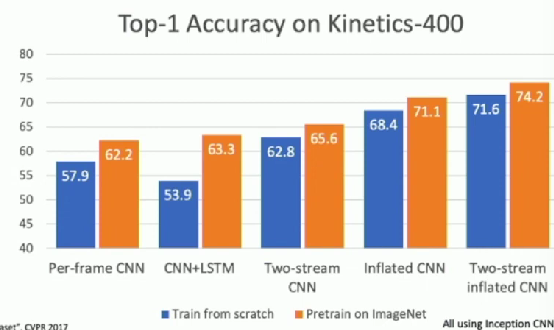
Performance
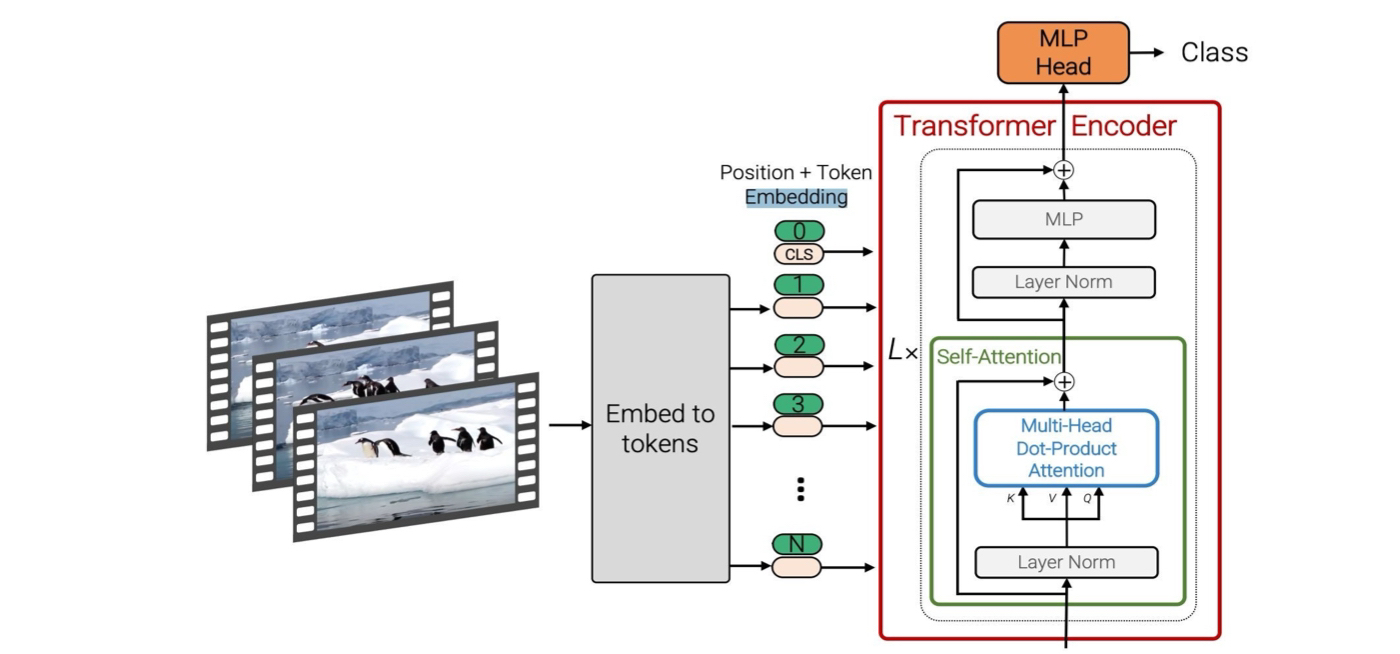
Vision Transformers for Video