Stochastic Gradient Descent
Approximate sum using a minibatch of examples 32/64/128 commons
# vanilla minibatch gradient descent
while True:
data_batch = sample_training_data(data, 256) # sample 256 examples
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad
SGD
Problems
Loss function has high condition number
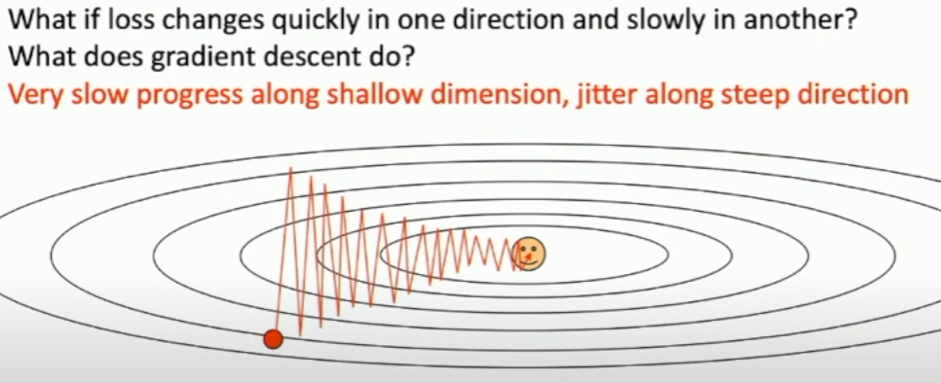
- step size is too big, overshooting
- small step size converges too slow
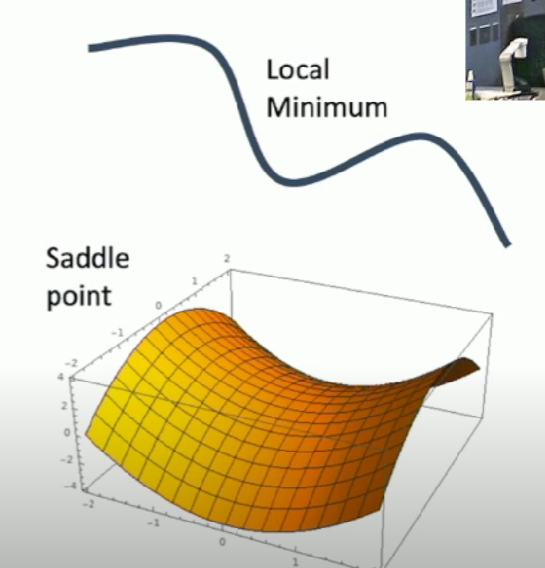
What if loss function has a local minimum or saddle point?
Zero gradient at both points so gradient descent might get stuck
Our gradients come from minibatches so they can be noisy!

Solution
SGD + Momentum
- Build up velocity as a running mean of gradients
- Rho gives friction; typically rho = 0.9 or 0.99
v = 0
for t in range(num_steps):
dw = compute_gradient(w)
v = rho * v + dw
w -= learning_rate * v
Success
- Carry us over local minima and saddle points
- Smooth out noise from batches
