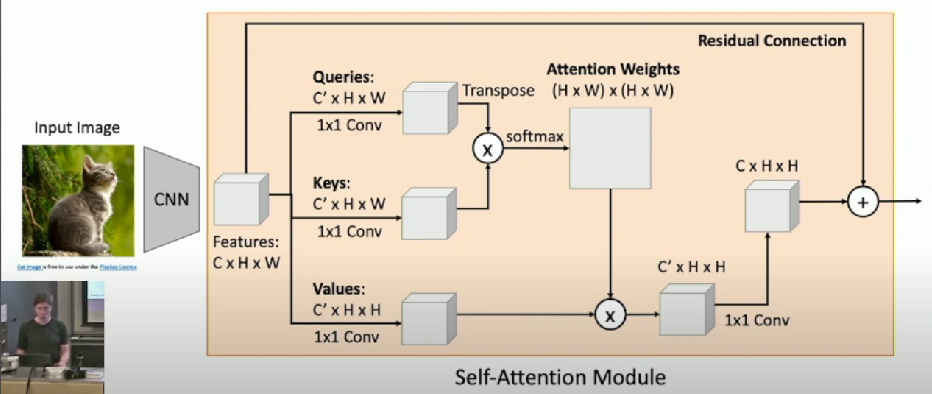
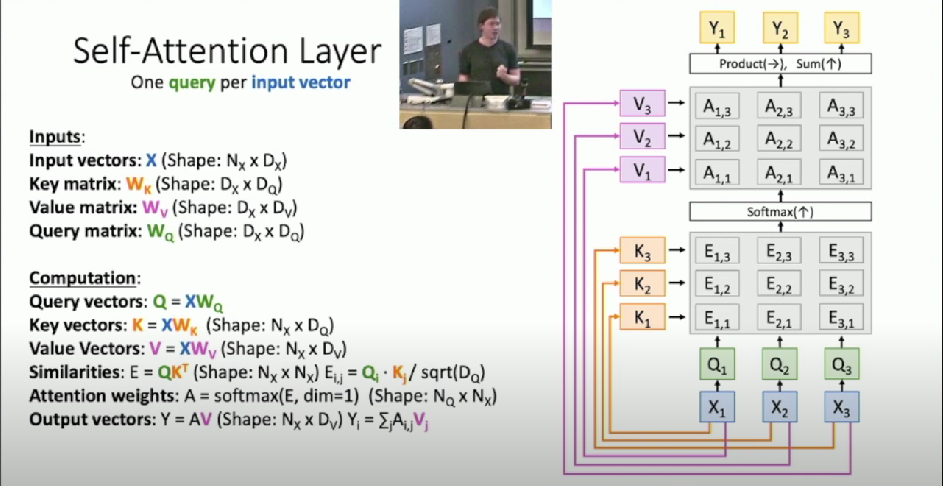
Self-Attention Layer
One query per input vector
- We can calculate the query vectors from the input vectors
- Defining a “self-attention” layer
- Query vectors are calculated using a FC layer
- No input query vectors anymore
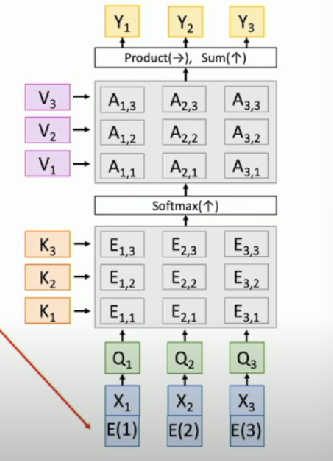
Permutation Equivariant
- Self-attention layer doesn’t care about the orders of the input
- Consider permuting the input vectors
- Outputs will be the same but permuted
Positional Encoding
Make processing position-aware
- Concatenate input with positional encoding
E can be learned lookup table, or fixed function
Masked Self-Attention Layer
Don’t let vectors “look ahead” in the sequence
- Only use information from the past
Used for language modeling - predict next word

Multihead Self-Attention Layer
Use
- Query dimension
- Number of heads

Example: CNN with Self-Attention