Pooling Layers
Another way to downsample
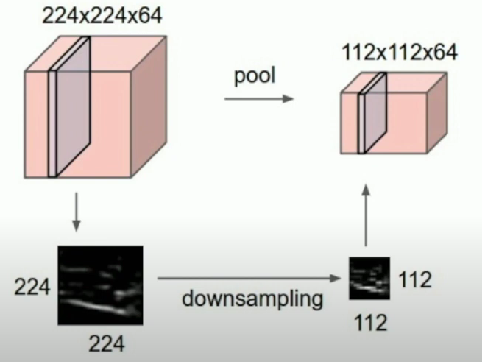
Input
C x H x W
Hyperparameters
- Kernel size: K
- Stride: S
- Pooling function (max, avg)
Output
C x H’ x W’ where
- H’ = (H - K) / S + 1
- W’ = (W - K) / S + 1
Max Pooling
- Pick Max value in the region
- Often use same kernel size as stride so there is no overlap
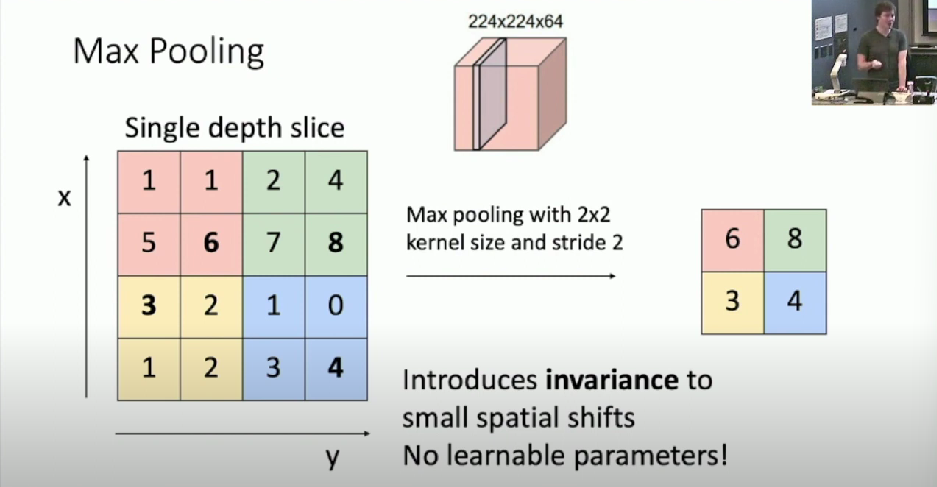
- Invariance: Max region may still be the same with small shifts
- No learnable parameters
Similarly, there can be average pooling