Optimization
How we find the best W based on Loss Function
Examples of optimization
- Random Search (BAD)
- Follow the slope (Works well in practice)
What is the slope?
In multiple dimensions, the Gradient is the vector of partial derivatives along each dimension
The slope in any direction is the dot product of the direction with the gradient. The direction of steepest descent is the negative gradient
Gradient check
Sanity check to make sure analytic gradient makes sense using numerical gradient
Learning Rate
First-Order Optimization
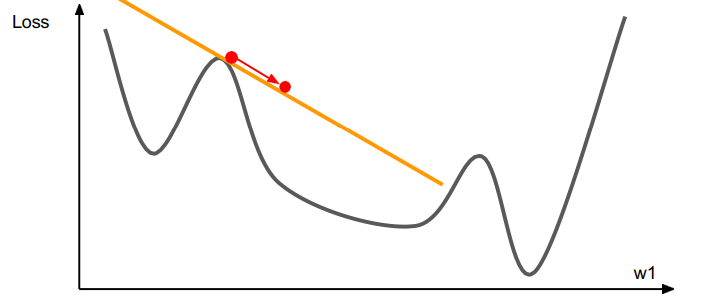
- Use gradient to make linear approximation
- Step to minimize the approximation
Gradient Descent
Stochastic Gradient Descent
AdaGrad
Adam
In practice, Adam is a good default choice
- SGD + Momentum can outperform Adam but may require more tuning (Learning rate and schedule)
- If you can afford to do full batch updates then try out L-BFGS
Second-Order Optimization
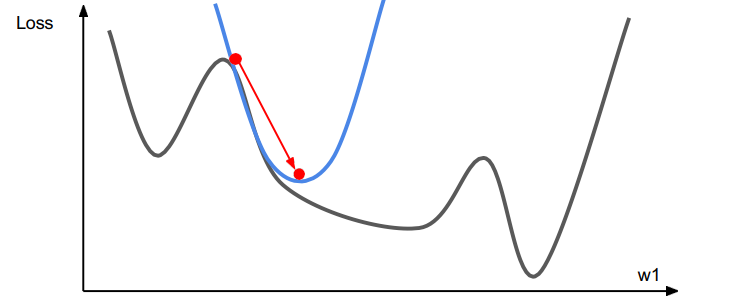
- Use gradient and Hessian to make quadratic approximation
- Step to minimize the approximation
IMPRACTICAL!!
