Neural Networks
Feature Extraction
Before
Linear score function:
Now
2-layer Neural Network:
3-layer Neural Network:
Activation Function
Fully-connected network
AKA Multi-layer perceptron
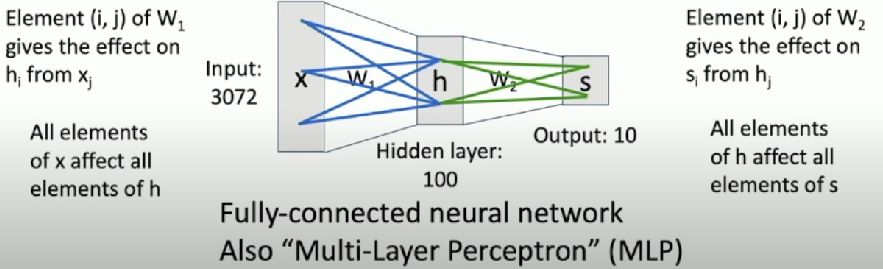
Neural Net
- First layer is bank of templates
- Second layer recombines templates

Deep Neural Networks
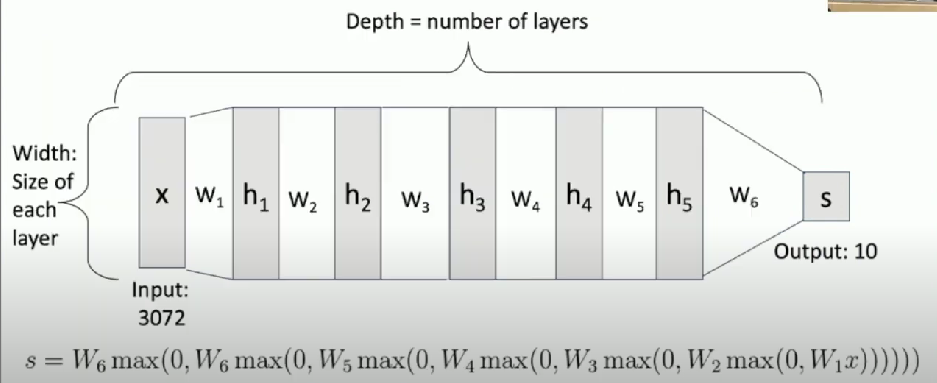
More hidden layers = more capacity

Faq
Are we overfitting with too many hidden layers?
Should we reduce the number of hidden layers?
Don’t regularize with size; instead use stronger L2

Universal Approximation
A neural network with one hidden layer can approximate any function
Examples
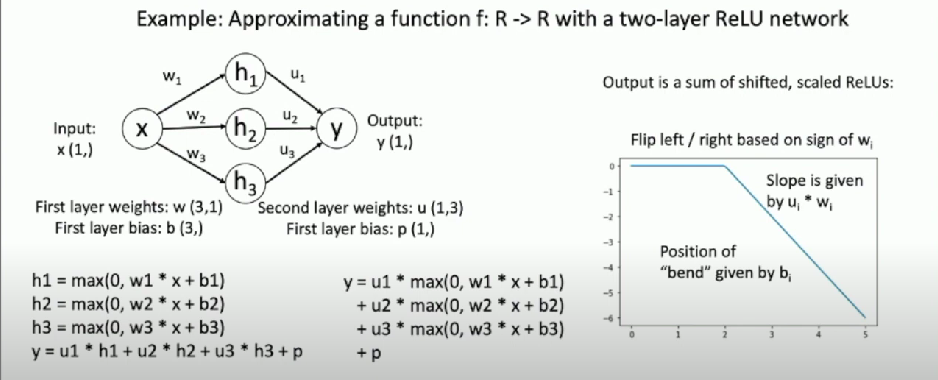

Convex Function
A function
- This means that the secant line between any two points of a function always lies above the function

A convex function is a (multidimensional) bowl
- Easy to optimize
- Converging to global minimum
Linear classifiers optimize a convex function
Most neural networks need Non-convex optimization
- Few or no guarantees about convergence
- Seems to work anyways lol