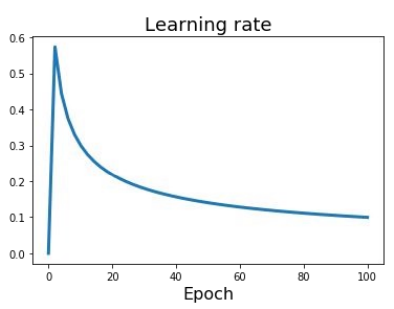
Learning Rate
Stochastic Gradient Descent, AdaGrad, Adam all have learning rate as a hyperparameter
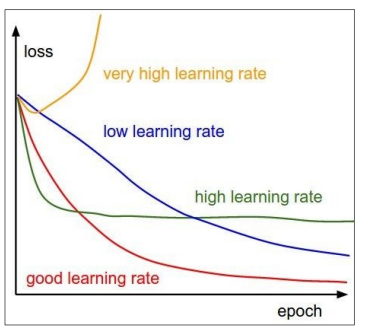
Which one of these learning rates is best to use?
All of them! Start with large learning rate and decay over time
Learning Rate Decay
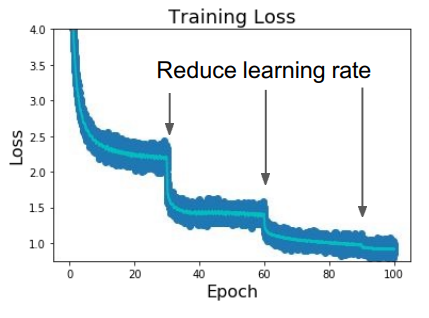
Reduce learning rate at a few fixed points.
- E.g. for resNets, Multiply LR by 0,1 after epochs 30, 60, and 90.
Examples of decay: - Cosine
- Two Hyperparameters
- No new hyperparameters
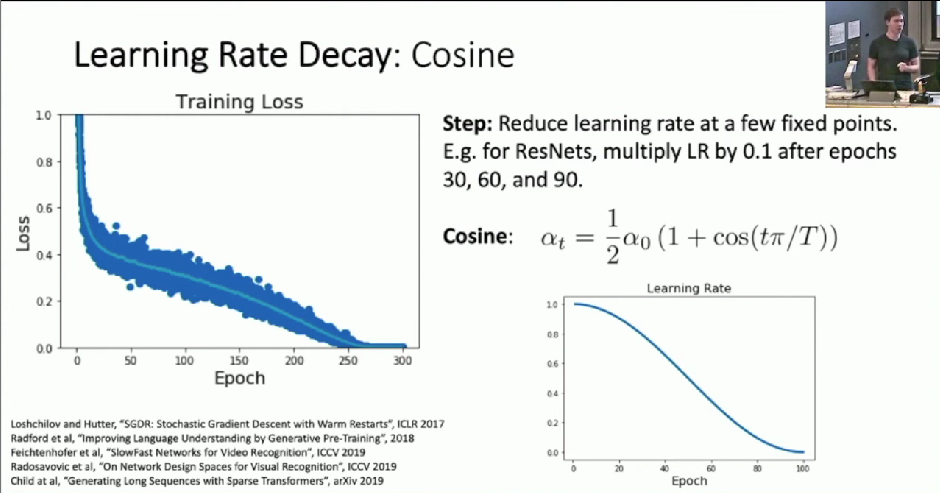
- Linear
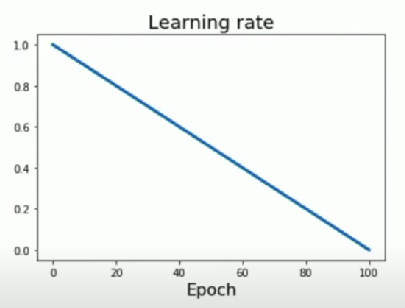
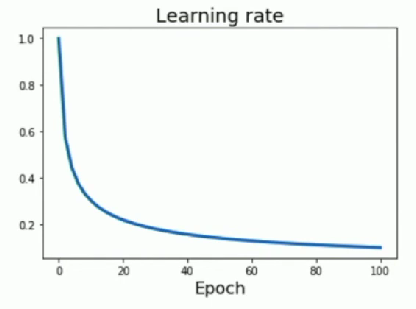
- Inverse sqrt
- Not a lot of time in high learning rate
- A lot of time in low learning rate
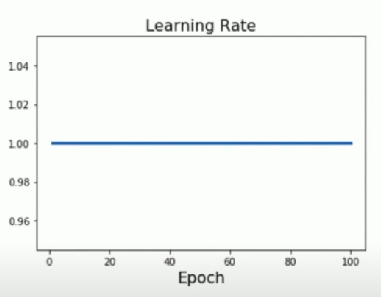
- constant
- Works well most of the time
- Works well most of the time
Linear warmup
High initial learning rates can make loss explode
Linearly increasing learning rate from 0 over the first ~5000 iterations can prevent this