Dropout
In each forward pass, randomly set some neurons to zero
- Probability of dropping is a Hyperparameters
- 0.5 is common
Why do we want this?
Forces the network to have a redundant representation
- Prevents co-adaptation of features

Dropout is a large ensemble of models
- Each binary mask is one model
Problems: Test Time
Dropout makes our output random!
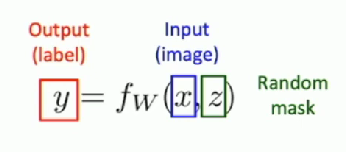
Want to “average out” randomness at test-time
- this integral seems hard…
Approximate the integral
At test time, drop nothing and multiple by dropout probability
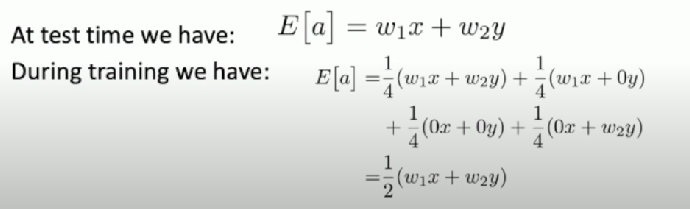
Inverted Dropout
Do the re-scaling during training time rather than test time
Architecture
Dropout is usually applied in the fully-connected layers
- later architectures use global average pooling instead
- they don’t use dropout