Diffusion
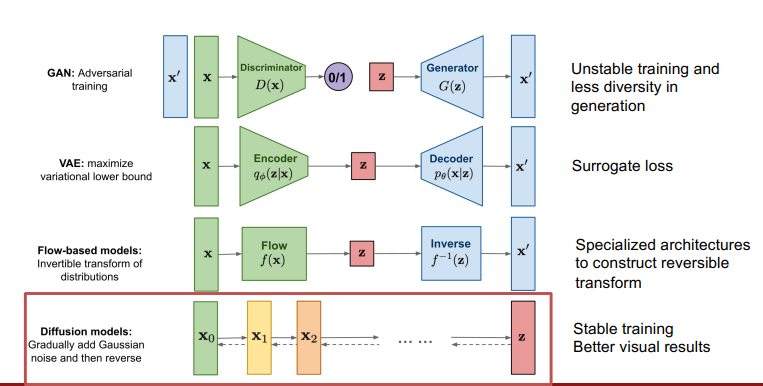
Add Gaussian noise and then reverse
Forward diffusion process:
- Gradually adds noise to input
Reverse denoising process: - Learns to generate data by denoising

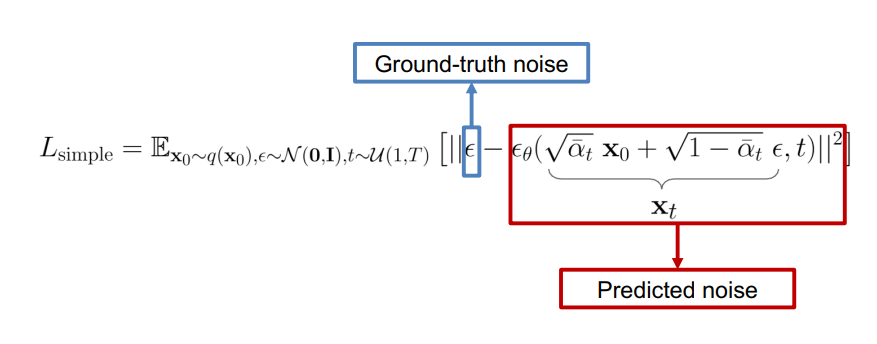
Training Objective
Network structure
Diffusion models often use U-Net architectures with ResNet blocks and Self-Attention Layer to represent
Time representation: Sinusoidal positional embeddings or random Fourier features
- Time features are fed to the residual blocks using either simple spatial addition or using adaptive group normalization layers

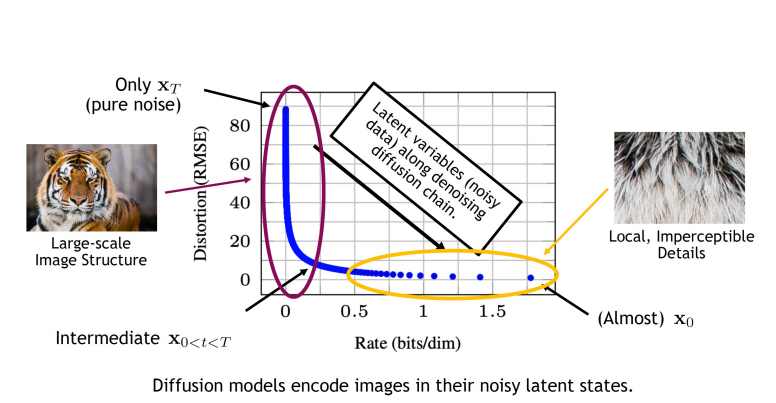
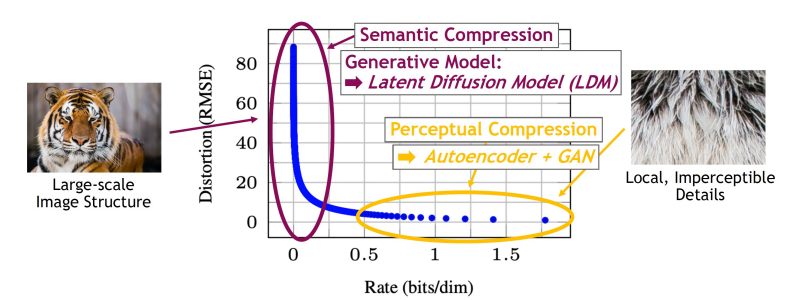
Latent Diffusion Models
Map data into compressed latent space
Train diffusion model efficiently in latent space

Advantages
- Compressed latent space: Train diffusion model in lower resolution
- Computationally more efficient
- Regularized smooth / compressed latent space
- Easier task for diffusion model and faster sampling
- Flexibility
- Autoencoders can be tailored to data
Condition information is fed into the latent diffusion model by cross-attention
Query:
- Visual features from U-Net
- Key and value: text features
Compression and Encoding
Diffusion Model
Latent Diffusion Model
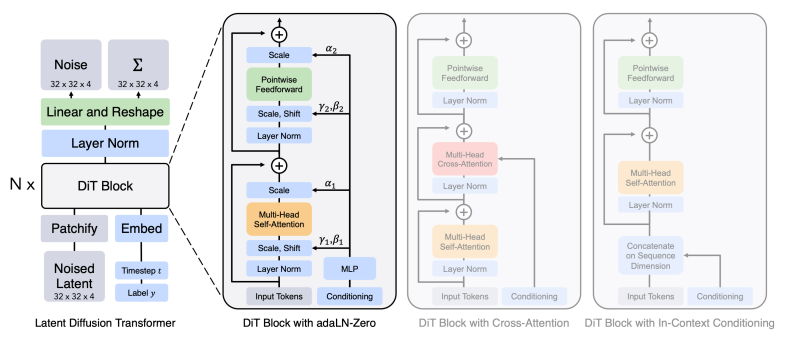
Diffusion Transformers
- Replace U-Net with Transformers