CNN Architectures
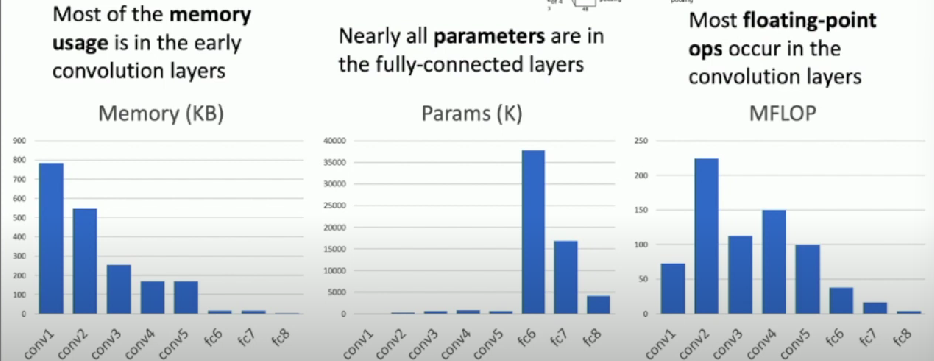
AlexNet (8 Layers)
- 227 x 227 inputs
- 5 Convolution Layers
- Max Pooling
- 3 fully-connected layers
- ReLU Non-linearities

ZFNet: A Bigger AlexNet (8 Layers)
Bigger networks work better?
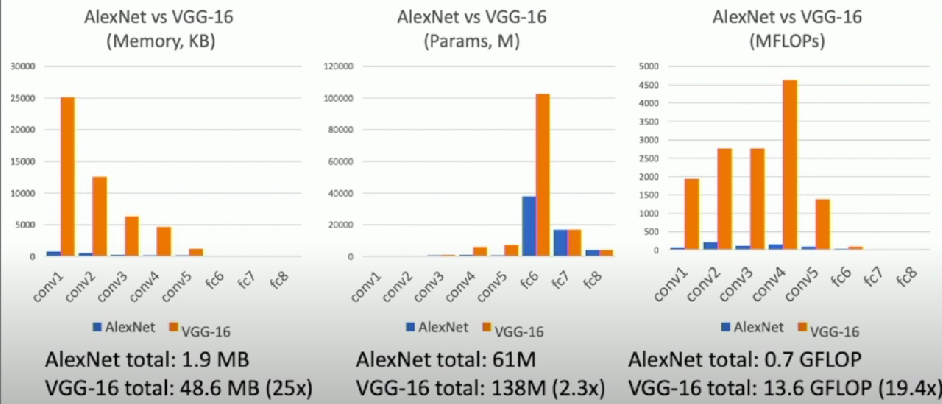
VGG (19 Layers)
Design rules
- All conv are 3x3 stride 1 pad 1
- All max pool are 2x2 stride 2
- After pool, double number of channels
Network has 5 convolutional stages:
- conv-conv-pool
- conv-conv-pool
- conv-conv-pool
- conv-conv-conv-pool
- conv-conv-conv-pool
Choices
Two conv of 3x3 has same receptive field as one 5x5
- Easier to compute

Why use bigger kernel sizes when I can stack 3x3s?
We want each spatial resolution to take the same amount of computation
- Half the spatial size
- Double the number of channels
AlexNet vs VGG: Much bigger network!
GoogLeNet (22 Layers)
Focus on Efficiency!
- Reduce parameter count
- Memory usage
- Computation
Stem network
Aggressively downsamples input
- Usually large computation at the beginning
Compare to VGG

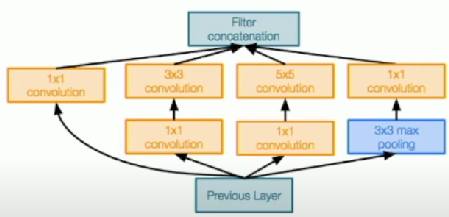
Inception Module
Local unit with parallel branches
Local structure repeated many times throughout the network
Global Average Pooling
Use global average pooling to collapse spatial dimensions, and one linear layer to produce class scores
Auxiliary Classifiers
Problem
Training using loss at the end of the network didn’t work well:
- Network is too deep
- Gradients don’t propagate cleanly
Solution (hacky)
Attach ‘auxiliary classifiers’ at several intermediate points in the network that also try to classify image and receive loss
Batch Normalization solved this issue
- Came after GoogLeNet
Residual Networks
Once we have Batch Normalization, we can train networks with 10+ layers
Deeper model does worse than shallow model!
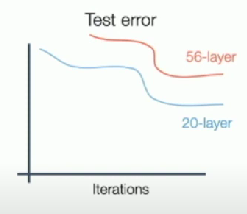
This is an optimization problem. Deeper models are harder to optimize, and in particular don’t learn identity functions to emulate shallow models
Residual blocks
Change the network so learning identity functions with extra layers is easy

Bottleneck Block

Able to train very deep networks
Deeper networks do better than shallow networks
Improving ResNets
Re-organize blocks

Parallel bottleneck blocks (ResNeXt)

Densely Connected Neural Networks
- Alleviates vanishing gradients
- Strengthens feature propagation
- Encourages feature reuse
MobileNets: Tiny Networks
Neural Architecture Search
Automating neural architecture creation
- One network (controller) outputs network architectures
- Sample child networks from controller and train them
- After training a batch of child networks, make a gradient step on controller network
- Over time, controller learns to output good architectures