Choosing Hyperparameters
With tons of GPUs
Grid Search
Choose several values for each hyperparameter
Often space choices log-linearly
Example:
- Weight decay:
- Learning rate:
Evaluate all possible choices on this hyperparameter grid
This is expensive!!!
Random Search
Choose several values for each hyperparameter
Often space choices log-linearly
Example:
- Weight decay: log-uniform on
- Learning rate: log-uniform on
Run many different trials
Comparison
More samples for each hyperparameter individually

Choosing Hyperparameters
Without tons of GPUs
Step 1: Check initial loss
Turn off weight decay, sanity check loss at initialization
- e.g. log(C) for Softmax Classifier with C classes
Step 2: Overfit a small sample
Try to train to 100% training accuracy on a small sample of training data
- ~5-10 minibatches
- fiddle with architecture, learning rate, weight initialization
- Turn off regularization
Loss not going down? → LR too low, bad initialization
Loss explodes to Inf or NaN? → LR too high, bad initialization
Step 3: Find Learning Rate that makes loss go down
Use the architecture from the previous step
- Use all training data
- Turn on small weight decay
- Find a learning rate that makes the loss drop significantly within ~100 iterations
Good learning rates to try:
Step 4: Coarse grid, train for ~1-5 epochs
Choose a few values of learning rate and weight decay around what worked from Step 3
- Train a few models for ~1-5 epochs
Good weight decay to try:
Step 5: Refine grid, train longer
Pick best models from Step 4
- train them for longer\
- ~10-20 epochs
- without learning rate decay
Step 6: Look at learning curves
Loss and accuracy curves
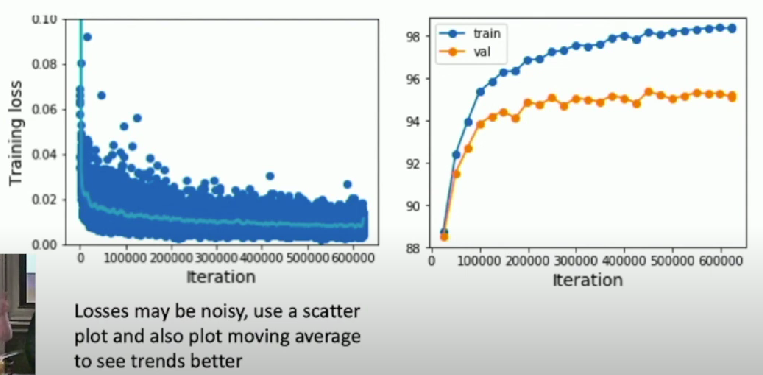
Step 7: Go to step 5
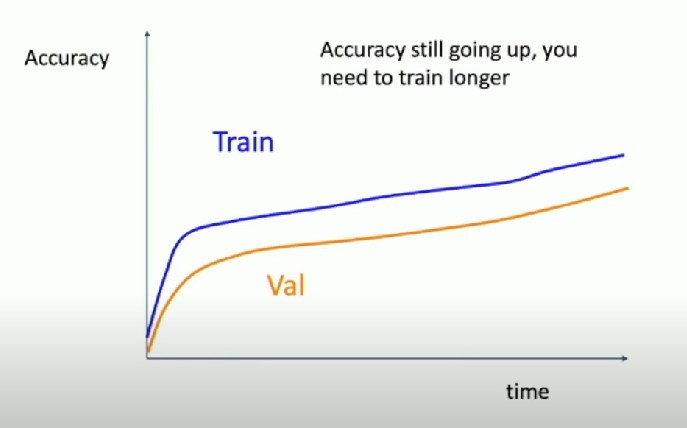
Scenarios
Things are going well, just train longer
Overfitting

Underfitting
