Batch Normalization
“Normalize” the outputs of a layer so they have zero mean and unit variance

Input
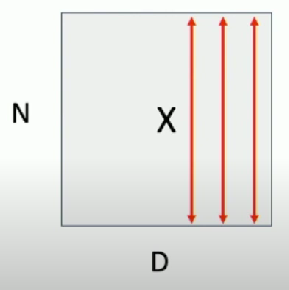

What if zero-mean, unit variance is too hard of a constraint?
Learnable scale and shift parameters:

Test-Time
Don’t want estimates to depend on minibatch

Usually insert batch normalization after fully connected or convolutional layers, and before nonlinearity
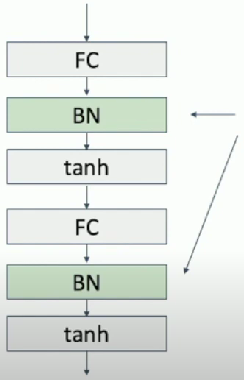
Pros
- Makes deep networks much easier to train
- Allows high learning rates, faster convergence
- Networks become more robust to initialization
- Acts as regularization during training
- Zero overhead at test-time: can be fused with conv!

Cons
- Not well-understood theoretically
- Behaves differently during training and testing
- This is a very common source of bugs