Attention
Problem: Sequence to Sequence (Translation)
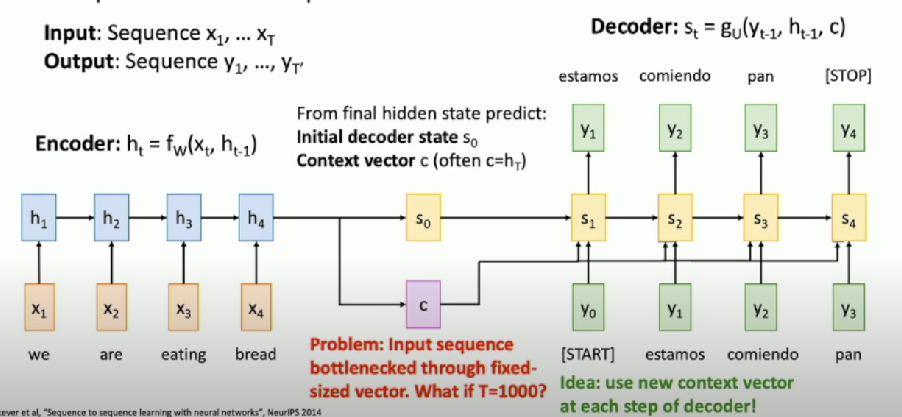
Input sequence bottlenecked through fixed-sized vector. What if T = 1000?
Idea:
- Use new context vector at each step of decoder
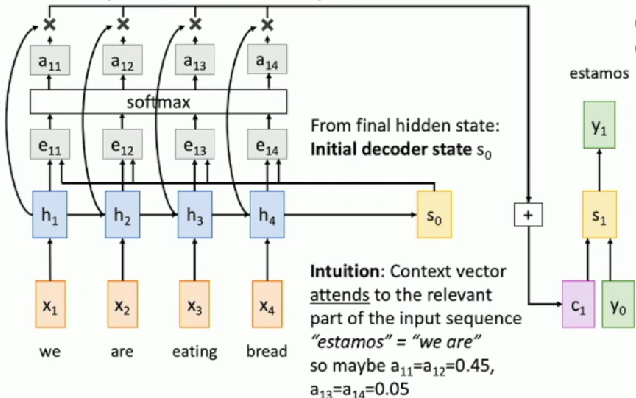
- Use attention
- Compute (scalar) alignment scores
( is an MLP)
- Normalize alignment scores to get attention weights
, - Softmax
- Compute context vector as linear combination of hidden states
- Use context vector in decoder
- Compute (scalar) alignment scores
Timestep = 2
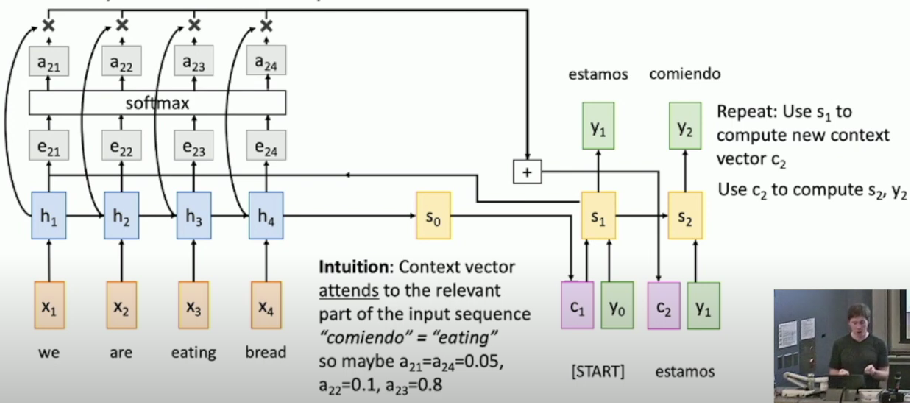
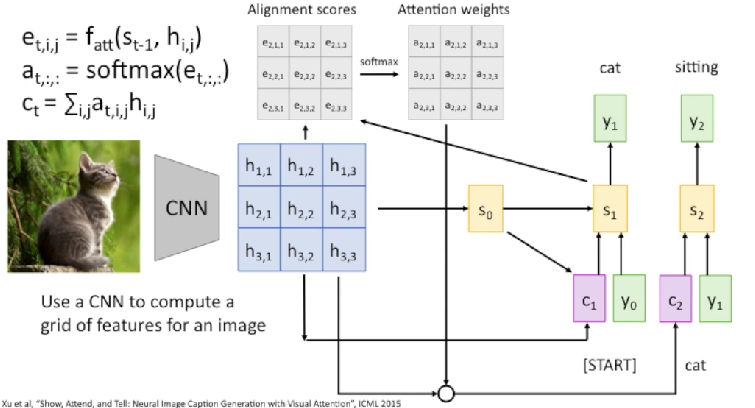
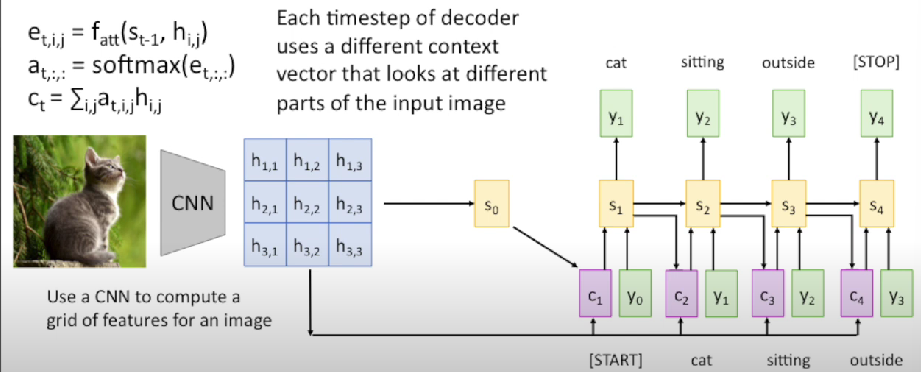
Use a different context vector in each timestep of decoder
- Input sequence not bottlenecked through single vector
- At each timestep of decoder, context vector “looks at” different parts of the input sequence
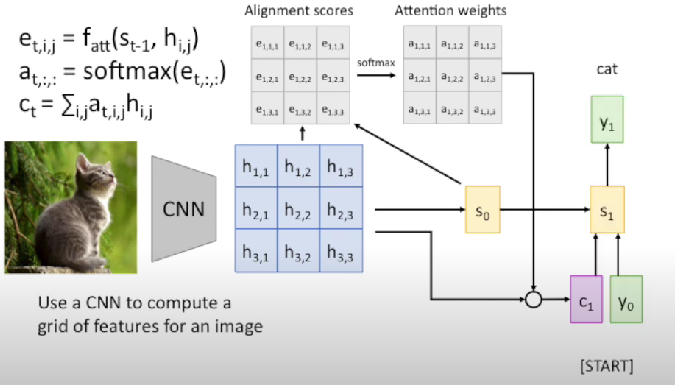
Image Captioning with RNNs and Attention
Problem
Input: Image
Output: Sequence
Steps
- Extract spatial features form a pretrained CNN
- Compute alignment scores
- Normalize alignment scores to get attention weights
- Compute context vector as linear combination of hidden states
- Use context vector in decoder
Timestep = 1
Timestep = 2
Timestep = 4
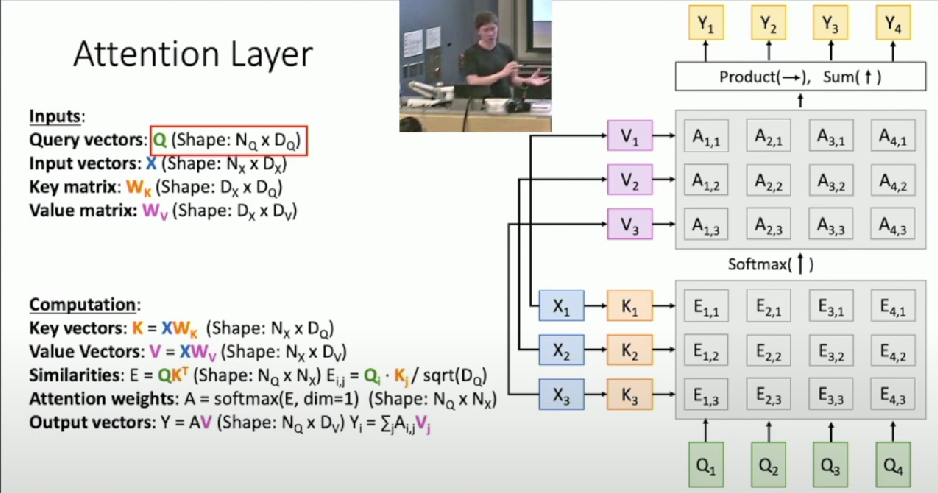
General Attention Layer
Inputs
Query vector: q (Shape
Input vectors: X (Shape:
Similarity function:
Computation
Alignment:
Attention:
Output:
Outputs
Context vector: c (Shape
Changes for generalization
- Use scaled dot product for alignment
- Large similarities will cause softmax to saturate and give vanishing gradients
- Divide by
to reduce effect of large magnitude vectors
- Multiple query vectors
- Separate key and value