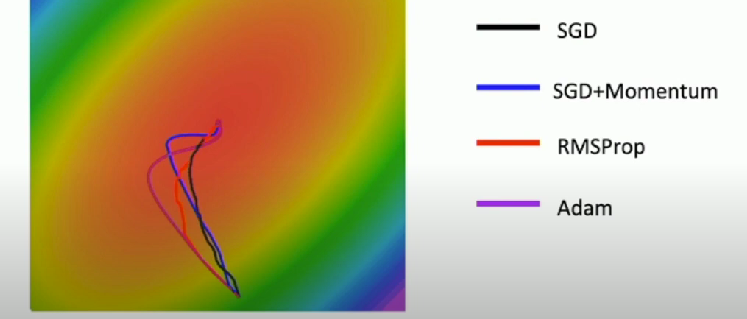
Adam (almost)
moment1 = 0
moment2 = 0
while True:
dw = compute_gradient(w)
moment1 = beta1 * moment1 + (1 - beta1) * dw
moment2 = beta2 * moment2 + (1 - beta2) * dw * dw
w -= learning_rate * moment1 / (np.sqrt(moment2) + 1e-7)
What happens at first timestamp?
Moments initialized as 0 so first steps will be biased towards 0
Adam (full form)
Bias Correction
moment1 = 0
moment2 = 0
for t in range(num_steps):
dw = compute_gradient(w)
moment1 = beta1 * moment1 + (1 - beta1) * dw
moment2 = beta2 * moment2 + (1 - beta2) * dw * dw
moment1_unbias = moment1 / (1 - beta1 ** t)
moment2_unbias = moment2 / (1 - beta2 ** t)
w -= learning_rate * moment1_unbias / (np.sqrt(moment2_unbias) + 1e-7)
Adam with beta1 = 0.9 and beta2 = 0.99, and learning_rate = 1e-3, 5e-4, 1e-4 is a great starting point for many models!