AdaGrad
Added element-wise scaling of the gradient based on the historical sum of squares in each dimension
grad_squared = 0
while True:
dx = compute_gradient(x)
grad_squared += dx * dx
x -= learrning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
What happens with AdaGrad
- Progress along “steep” directions is damped
- Progress along “flat” directions is accelerated
if ran for too long
grad_squared may get too big and stop making progress
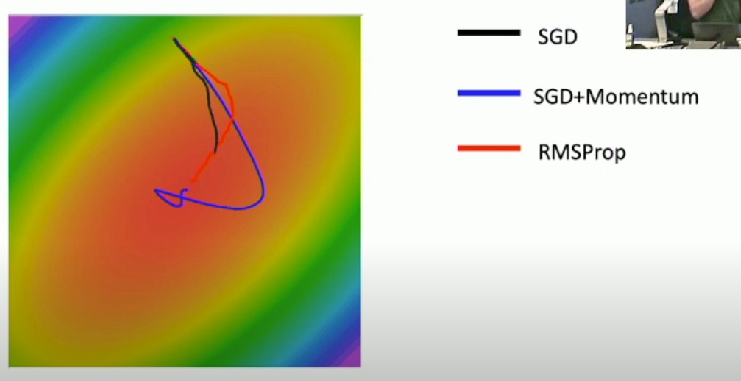
RMSProp (Leaky-AdaGrad)
grad_squared = 0
while True:
dx = compute_gradient(x)
grad_squared = decay_rate * grad_squared + (1 - decay_rate) * dx * dx
x -= learrning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
Extra friction term to decay our running average of square gradients
- Make better progress
- Not slow down as training gets longer