Activation Function
2-layer Neural Network:
max is the activation function
The function
What if we build a neural network with no activation function?
So we get,
This is a linear classifier
Examples of Activation Functions
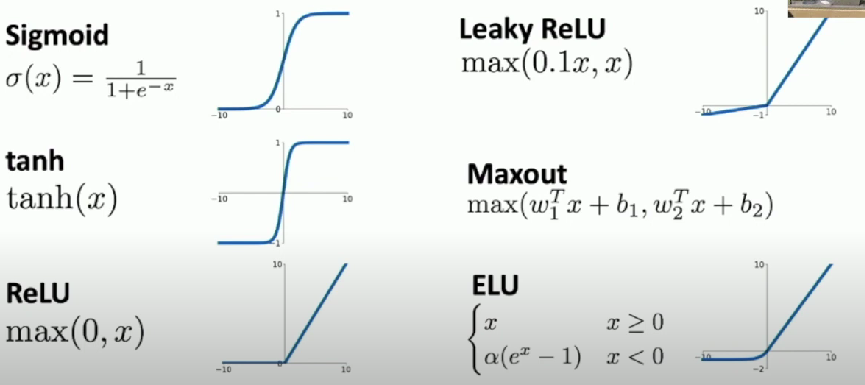
ReLU is a good default choice
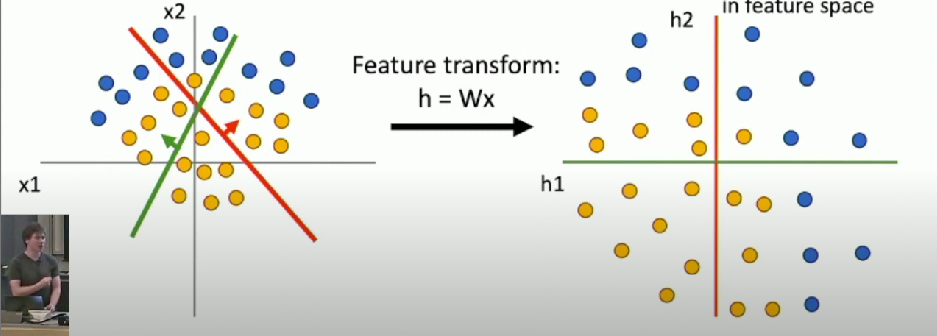
Space warping
Consider a linear transform: h = Wx where x, h are both 2-dimensional
- Not linearly separable in original space or feature space
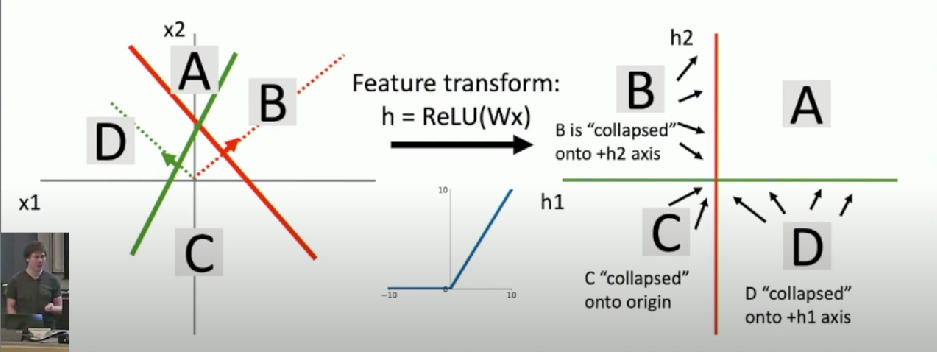
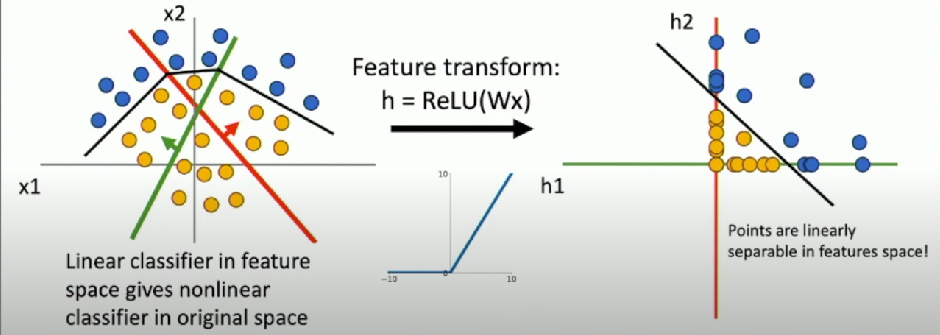
Consider a neural net hidden layer:
h = ReLU(Wx) = max(0, Wx) where x, h are both 2-dimensional
- Not linearly separable in original space but linearly separable in feature space
Sigmoid
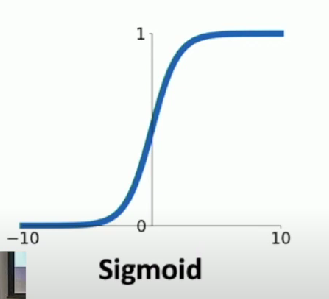
- Squashes number to range [0,1]
- Historically popular since they have nice interpretation as a saturating “firing rate” of a neuron
3 Problems
- Saturate neurons “kill” the gradients
- Flat areas kill the gradient
- Sigmoid outputs are not zero-centered
- Always all positive or all negative
- exp() is a bit compute expensive
Tanh
Shifted sigmoid

- Squashes numbers to range [-1, 1]
- zero centered (nice)
- still kills gradients when saturated
ReLU (Rectified Linear Unit)

- Does not saturate (in +ve region)
- Very computationally efficient
- Converges much faster
Problems
- Not zero-centered output
What happens when x < 0?
Gradient will be identically 0
- Learning cannot proceed
Dead ReLU
- will never activate/update
Sometimes initialize ReLU neurons with slightly positive bias
Leaky ReLU
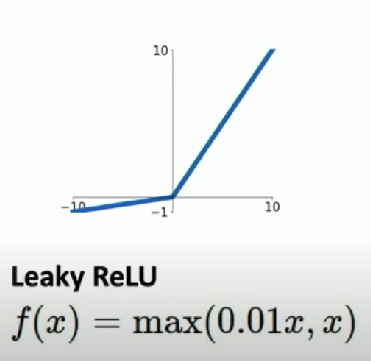
- Does not saturate
- Computationally efficient
- Converges much fast
- Will not “die”
0.01is a Hyperparameters
Parametric ReLU (PReLU)
Exponential Linear Unit (ELU)
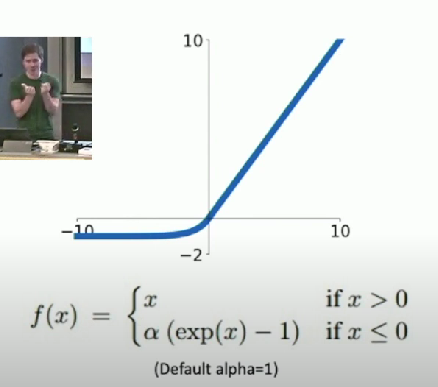
- All benefits of ReLU
- Closer to zero mean outputs
- Negative saturation regime compared with Leaky ReLU
- Adds some robustness to noise
Computation requires exp()
Scaled Exponential Linear Unit (SELU)
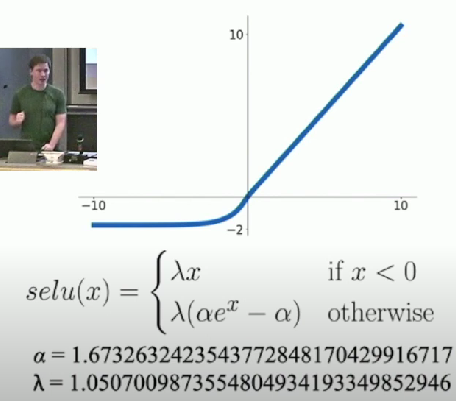
- Scaled version of ELU that works better for deep networks
- “Self-Normalizing” property
- Can train deep SELU networks without Batch Normalization
Comparison
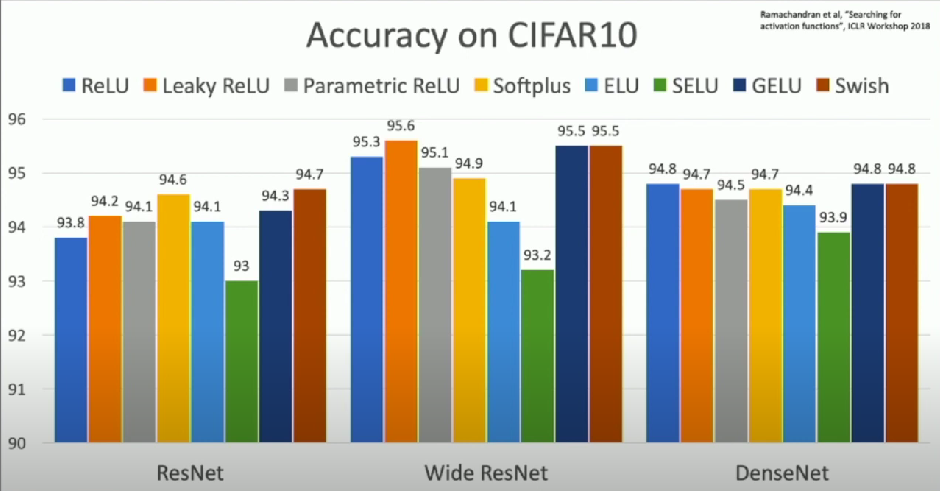
- Inconsistent results
Just use ReLU
- Try out Leaky ReLU / ELU / SELU / GELU if you need to squeeze that last 0.1%
- Don’t use sigmoid or tanh