Query Optimization
Thousands of possible query plans for a given query that differ by orders of magnitude in their performance
- Alternative plans that derive from equivalences in RA
- Alternative plans that choose different implementations of RA operations
How is the best plan found?
- Review basic always good transformations
- Cost-based join order selection in next unit
df
→ Finding an optimal plan is computationally not feasible
General Approach
- Generate all physical plans equivalent to the query
- Choose the plan having the lowest cost
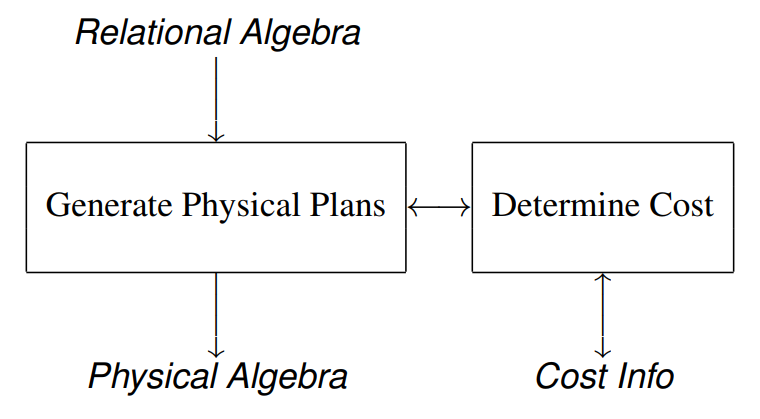
All Physical plans equivalent to the query
- Can’t be done in general
- Undecidable if a query is unsatisfiable
- Equivalent to an empty plan
- Very expensive for even conjunctive queries
- Selecting the best join order
In practice
- Consider only plans of a certain form (restrictions on the search space)
- Focus on eliminating really bad queries
Plans having the lowest cost
Not possible to run the plan to find out
Estimate the cost based on statistical metadata collected by the DBMS on database instances
- Uniformity: All possible values of an attribute are equally likely to appear in a relation
- Independence: Likelihood that an attribute has a particular value in a tuple does no depend on values of other Attributes